
TXT方法和word一样的,只是请求目录不一样
import re
import os
import time
import json
import random
import requests
import logging
import glob
import threading
import queue
import traceback
import natsort
import sys
import shutil
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, NoSuchElementException
# 版权信息
COPYRIGHT_INFO = """
============================================================
吾爱破解论坛 - www.52pojie.cn
作者:pansuan
============================================================
警告:本工具仅供技术交流与学习使用,严禁用于商业倒卖!
任何未经授权的商业使用均属侵权行为,将承担法律责任。
============================================================
"""
# 定义全局常量
OUTPUT_BASE_DIR = r"C:\Users\16272\Downloads\文库"
os.makedirs(OUTPUT_BASE_DIR, exist_ok=True)
# 精简日志配置
logging.basicConfig(
level=logging.INFO,
format='%(message)s'
)
class NetworkCaptureThread(threading.Thread):
"""捕获核心文档数据请求的线程"""
def __init__(self, driver):
super().__init__()
self.driver = driver
self.captured_urls = queue.Queue()
self.running = True
self.daemon = True
self.last_capture_time = time.time()
def run(self):
"""捕获文档数据请求"""
while self.running:
try:
logs = self.driver.get_log('performance')
for entry in logs:
try:
message = json.loads(entry['message'])['message']
if message['method'] == 'Network.requestWillBeSent':
url = message['params']['request']['url']
if ('wkretype.bdimg.com/retype/text/' in url and
'callback=wenku_' in url):
self.captured_urls.put(url)
self.last_capture_time = time.time() # 更新最后捕获时间
except:
continue
time.sleep(0.5)
except:
time.sleep(1)
def stop(self):
self.running = False
def get_captured_urls(self):
urls = set()
while not self.captured_urls.empty():
urls.add(self.captured_urls.get())
return list(urls)
def get_last_capture_time(self):
return self.last_capture_time
class BaiduWenkuDownloader:
def __init__(self):
self.driver = None
self.profile_path = None
self.doc_id = None
self.doc_title = "百度文库文档"
self.doc_url = None
self.data_urls = []
self.capture_thread = None
self.chrome_driver_path = r"D:\python\pythonProject1\xuexi\chromedriver.exe"
self.output_dir = OUTPUT_BASE_DIR
self.session = requests.Session() # 使用Session复用连接
self.session.headers.update({
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
})
def setup_driver(self):
"""设置并返回 WebDriver"""
chrome_options = Options()
# 启用无头模式
chrome_options.add_argument("--headless=new")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("--window-size=1920,1080")
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
chrome_options.set_capability("goog:loggingPrefs", {'performance': 'ALL'})
if self.profile_path and os.path.exists(self.profile_path):
chrome_options.add_argument(f"--user-data-dir={self.profile_path}")
try:
service = Service(executable_path=self.chrome_driver_path)
return webdriver.Chrome(service=service, options=chrome_options)
except Exception as e:
logging.error(f"初始化失败: {str(e)}")
return None
def get_or_create_profile(self):
"""获取或创建浏览器配置文件"""
profile_path = os.path.join(os.getcwd(), "chrome_profile")
os.makedirs(profile_path, exist_ok=True)
return profile_path
def get_total_pages(self):
"""获取文档总页数"""
try:
# 查找页数说明元素
WebDriverWait(self.driver, 15).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "div.page-tips"))
)
# 查找所有页数说明元素
page_tips_elements = self.driver.find_elements(By.CSS_SELECTOR, "div.page-tips")
print(f"找到 {len(page_tips_elements)} 个页数提示元素")
# 遍历元素查找页数
for element in page_tips_elements:
text = element.text
match = re.search(r'原始文档\s*共\s*(\d+)\s*页', text)
if match:
return int(match.group(1))
# 如果没找到,尝试估算
return self.estimate_page_count()
except:
# 如果失败则使用备用方法估算页数
return self.estimate_page_count()
def estimate_page_count(self):
"""估算文档页数"""
try:
# 尝试查找页面元素
pages = self.driver.find_elements(By.CSS_SELECTOR, ".page-item, .page-wrapper, .ppt-page")
if len(pages) > 0:
return len(pages)
# 尝试基于内容高度估算
page_height = self.driver.execute_script("return document.body.scrollHeight")
viewport_height = self.driver.execute_script("return window.innerHeight")
return max(1, round(page_height / viewport_height))
except:
return 1 # 默认值
def calculate_clicks_needed(self, total_pages):
"""通用的点击次数计算公式"""
# 基础规则:
# - 每100页点击1次
# - 至少点击1次
# - 最大10次
return min(10, max(1, (total_pages + 99) // 100))
def perform_fixed_clicks(self, clicks_needed):
"""执行固定次数的点击操作"""
# 先滚动到顶部确保按钮可见
self.driver.execute_script("window.scrollTo(0, 0);")
time.sleep(1)
for click_count in range(clicks_needed):
try:
# 尝试多种选择器查找展开按钮
selector = "div.btn.unfold.light, div.fold-button, div.moreBtn, div.unfold-btn, .more-btn"
expand_btn = WebDriverWait(self.driver, 5).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, selector))
)
# 滚动到按钮位置
self.driver.execute_script("arguments[0].scrollIntoView({behavior: 'smooth', block: 'center'});",
expand_btn)
time.sleep(0.5)
# 点击按钮
self.driver.execute_script("arguments[0].click();", expand_btn)
print(f"已点击展开按钮 {click_count + 1}/{clicks_needed}")
time.sleep(random.uniform(1.5, 2.5))
except Exception as e:
print(f"点击展开按钮时出错: {str(e)}")
# 如果找不到按钮,继续下一次尝试
pass
def handle_popups(self):
"""处理弹窗"""
try:
# 尝试点击继续阅读按钮
continue_btn = WebDriverWait(self.driver, 3).until(
EC.element_to_be_clickable(
(By.XPATH, "//div[contains(text(), '继续阅读') or contains(text(), '点击继续阅读')]"))
)
continue_btn.click()
print("已点击继续阅读按钮")
time.sleep(1)
except:
pass
try:
# 尝试关闭登录提示
close_btn = WebDriverWait(self.driver, 2).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "div.close-btn, span.banner-close, .dialog-close"))
)
close_btn.click()
print("已关闭弹窗")
except:
pass
def scroll_document_by_pages(self, total_pages):
"""智能滚动文档内容"""
# 计算分段数 - 更细的分段
segments = min(total_pages, 30) # 最多30段
print(f"将文档分为 {segments} 段进行滚动")
# 开始滚动
for i in range(1, segments + 1):
# 计算当前目标页
target_page = min(total_pages, round(i * total_pages / segments))
# 更新进度显示
sys.stdout.write(f"\r滚动进度: {target_page}/{total_pages} 页 [{i}/{segments}]")
sys.stdout.flush()
# 滚动到目标位置
self.scroll_to_page(target_page, total_pages)
# 随机延迟
time.sleep(random.uniform(0.3, 0.8))
# 处理新出现的按钮
if self.handle_expand_buttons_in_view():
print("\n检测到并点击了展开按钮")
# 最后滚动到底部确保所有内容加载
self.driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
# 滚动完成后清除进度显示
sys.stdout.write('\r')
sys.stdout.flush()
print("滚动完成")
def scroll_to_page(self, page_num, total_pages):
"""滚动到特定页码"""
try:
# 尝试通过ID定位
page_id = f"original-pageNo-{page_num}"
page_element = WebDriverWait(self.driver, 1).until(
EC.presence_of_element_located((By.ID, page_id))
)
self.driver.execute_script(
"arguments[0].scrollIntoView({behavior: 'auto', block: 'center', inline: 'center'});", page_element)
return
except:
try:
# 尝试通过页码文本定位
page_text = f"第{page_num}页"
page_element = WebDriverWait(self.driver, 1).until(
EC.presence_of_element_located((By.XPATH, f"//*[contains(text(), '{page_text}')]"))
)
self.driver.execute_script("arguments[0].scrollIntoView();", page_element)
except:
# 最后手段:按百分比滚动
percent = min(99, max(1, (page_num / total_pages) * 100)) # 避免0%和100%
self.driver.execute_script(f"window.scrollTo(0, document.body.scrollHeight * {percent / 100});")
def handle_expand_buttons_in_view(self):
"""处理当前视图中的展开按钮"""
try:
# 尝试查找展开按钮
selectors = [
"div.btn.unfold.light",
"div.fold-button",
"div.moreBtn",
"div.unfold-btn",
".more-btn",
"button:contains('展开')",
"button:contains('查看剩余全文')"
]
for selector in selectors:
try:
expand_btn = self.driver.find_element(By.CSS_SELECTOR, selector)
# 如果按钮可见则点击
if expand_btn.is_displayed():
self.driver.execute_script("arguments[0].click();", expand_btn)
time.sleep(1)
return True
except:
continue
except:
pass
return False
def extract_document_title(self):
"""提取文档标题"""
try:
title = self.driver.title
if title and "百度文库" in title:
title = title.replace("- 百度文库", "").strip()
clean_title = re.sub(r'[\\/*?:"<>|]', '', title)
return clean_title[:100] if len(clean_title) > 100 else clean_title
except:
return "百度文库文档"
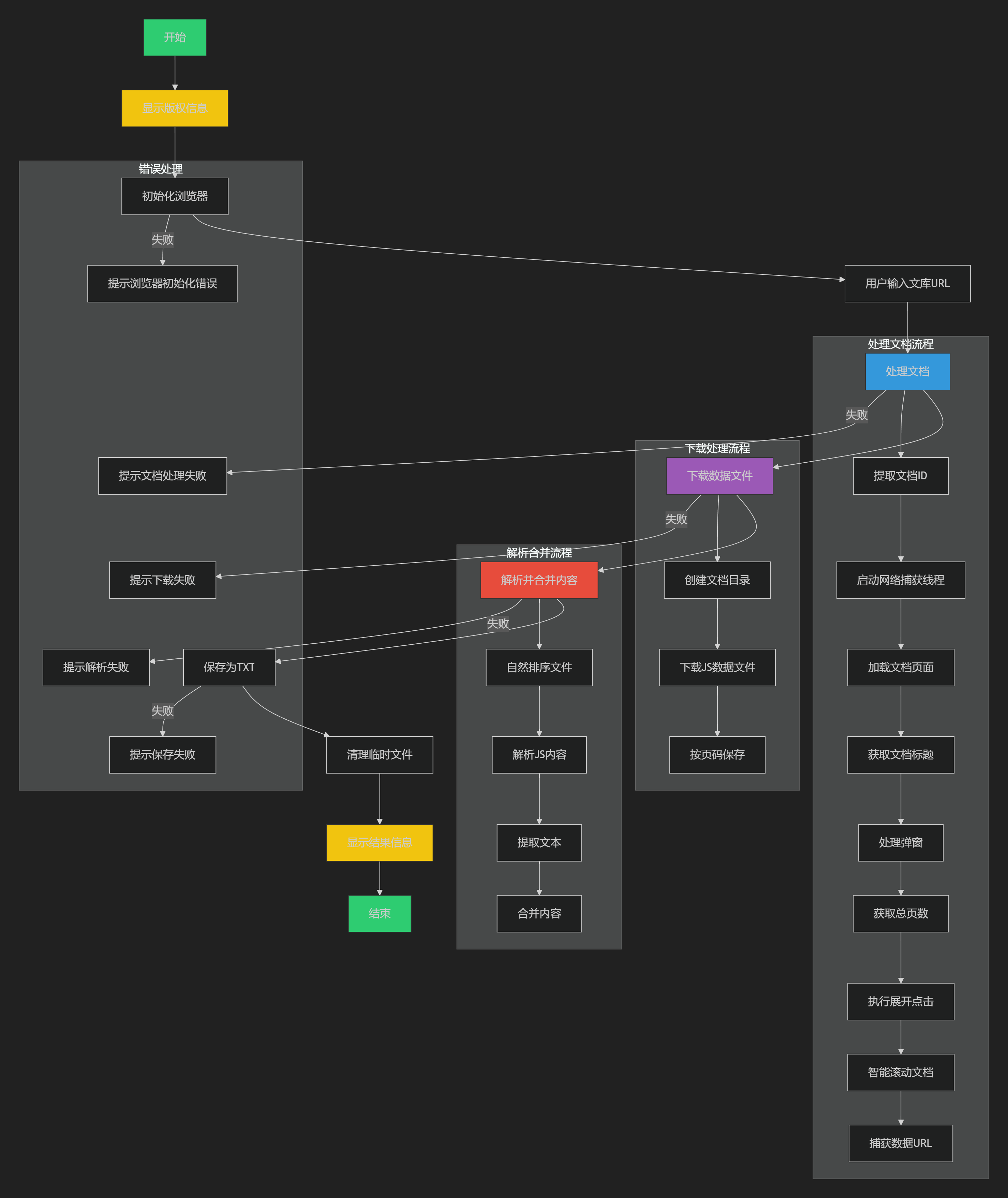
def process_document(self, doc_url):
"""处理文库文档"""
doc_id_match = re.search(r'/view/([a-f0-9]{24,40})', doc_url) or \
re.search(r'/docview/([a-f0-9]{24,40})', doc_url) or \
re.search(r'share/[a-f0-9]{32}/([a-f0-9]{24,40})', doc_url)
self.doc_id = doc_id_match.group(1) if doc_id_match else None
if not self.doc_id:
logging.error("无法从URL中提取文档ID")
return False
try:
print("启动网络捕获线程...")
self.capture_thread = NetworkCaptureThread(self.driver)
self.capture_thread.start()
print("正在加载文档页面...")
self.driver.get(doc_url)
time.sleep(5)
self.doc_title = self.extract_document_title()
print(f"文档标题: {self.doc_title}")
# 处理弹窗
print("处理弹窗...")
self.handle_popups()
# 获取文档实际页数
print("获取文档页数...")
total_pages = self.get_total_pages()
if total_pages is None:
total_pages = 1 # 默认值
print(f"检测到文档实际共 {total_pages} 页")
# 执行固定次数的点击
clicks_needed = self.calculate_clicks_needed(total_pages)
print(f"需要点击展开按钮 {clicks_needed} 次")
self.perform_fixed_clicks(clicks_needed)
# 智能滚动查看文档
if total_pages > 0:
print("开始滚动文档...")
self.scroll_document_by_pages(total_pages)
# 完成滚动后等待更多请求
print("等待捕获剩余请求...")
time.sleep(5)
# 检查最后捕获时间,如果最近有捕获则再等待
last_capture_time = self.capture_thread.get_last_capture_time()
if time.time() - last_capture_time < 3:
print("最近有捕获请求,再等待3秒...")
time.sleep(3)
# 获取数据URL
self.data_urls = self.capture_thread.get_captured_urls()
print(f"捕获到 {len(self.data_urls)} 个数据URL (期望: {total_pages} 个)")
# 如果捕获的数量少于页数,尝试再次滚动
if len(self.data_urls) < total_pages:
print(f"警告: 捕获数量({len(self.data_urls)})少于文档页数({total_pages})")
print("尝试额外滚动以捕获更多请求...")
# 重新滚动文档
self.scroll_document_by_pages(total_pages)
time.sleep(3)
# 再次获取数据URL
self.data_urls = self.capture_thread.get_captured_urls()
print(f"再次捕获后共有 {len(self.data_urls)} 个数据URL")
return True
except Exception as e:
logging.error(f"处理文档时出错: {str(e)}")
traceback.print_exc()
return False
def download_data_files(self):
"""下载文档数据文件"""
if not self.data_urls:
return []
# 为文档创建专用目录
doc_dir = os.path.join(self.output_dir, self.doc_id)
os.makedirs(doc_dir, exist_ok=True)
downloaded_files = []
print(f"开始下载 {len(self.data_urls)} 个数据文件...")
for i, url in enumerate(self.data_urls):
try:
# 提取页码作为文件名
match = re.search(r'pn=(\d+)', url)
page_num = int(match.group(1)) if match else i
save_path = os.path.join(doc_dir, f"{page_num:03d}.js")
if self.download_file(url, save_path):
downloaded_files.append(save_path)
sys.stdout.write(f"\r已下载: {i + 1}/{len(self.data_urls)}")
sys.stdout.flush()
time.sleep(0.2)
except Exception as e:
logging.error(f"下载失败: {str(e)}")
sys.stdout.write('\r')
sys.stdout.flush()
return downloaded_files
def download_file(self, url, save_path):
"""下载单个文件"""
try:
headers = {
"Referer": f"https://wenku.baidu.com/view/{self.doc_id}.html"
}
response = self.session.get(url, headers=headers, timeout=15)
response.raise_for_status()
with open(save_path, 'w', encoding='utf-8') as f:
f.write(response.text)
return True
except Exception as e:
print(f"\n下载失败: {url} - {str(e)}")
return False
def parse_js_file(self, js_file_path):
"""读取并解析JS文件内容"""
try:
with open(js_file_path, 'r', encoding='utf-8') as file:
js_content = file.read()
# 使用正则表达式提取JSON部分
match = re.search(r'wenku_\d+\((.*)\);?$', js_content, re.DOTALL)
if not match:
return None
try:
json_str = match.group(1)
return json.loads(json_str)
except json.JSONDecodeError:
return None
except Exception:
return None
def extract_text_from_single_page(self, page_data):
"""从单个页面的数据中提取文本"""
if not page_data:
return ""
# 处理不同的数据结构
if isinstance(page_data, list) and len(page_data) > 0:
page_obj = page_data[0]
elif isinstance(page_data, dict):
page_obj = page_data
else:
return ""
full_text = ""
if not isinstance(page_obj, dict) or 'parags' not in page_obj:
return ""
# 处理段落
for paragraph in page_obj['parags']:
if paragraph.get('t') == 'txt' and 'c' in paragraph:
text = paragraph['c'].replace('\r', '').strip()
text = re.sub(r'\s+', ' ', text) # 合并多个空白字符
full_text += text + '\n'
return full_text.strip()
def merge_js_files_to_txt(self, js_files, output_path):
"""合并多个JS文件到一个TXT文件"""
# 按文件名自然排序
sorted_files = natsort.natsorted(js_files)
all_content = ""
success_count = 0
print(f"开始解析 {len(sorted_files)} 个文件...")
for i, js_file in enumerate(sorted_files):
if not os.path.exists(js_file):
continue
# 解析JS文件
page_data = self.parse_js_file(js_file)
if not page_data:
print(f"解析失败: {os.path.basename(js_file)}")
continue
# 提取文本内容
text_content = self.extract_text_from_single_page(page_data)
if not text_content:
print(f"无文本内容: {os.path.basename(js_file)}")
continue
# 直接添加内容(无页码标记)
all_content += text_content + "\n\n"
success_count += 1
sys.stdout.write(f"\r解析进度: {i + 1}/{len(sorted_files)}")
sys.stdout.flush()
sys.stdout.write('\r')
sys.stdout.flush()
if success_count == 0:
return False
# 保存合并后的内容
try:
with open(output_path, 'w', encoding='utf-8') as file:
file.write(all_content.strip())
print(f"成功解析 {success_count}/{len(sorted_files)} 个文件")
return True
except Exception as e:
print(f"保存文件时出错: {str(e)}")
return False
def cleanup_temp_files(self):
"""清理临时文件"""
if self.doc_id:
doc_dir = os.path.join(self.output_dir, self.doc_id)
if os.path.exists(doc_dir):
try:
# 删除临时目录及其所有内容
shutil.rmtree(doc_dir)
print(f"已清理临时文件: {doc_dir}")
except Exception as e:
print(f"清理临时文件时出错: {str(e)}")
def main(self):
print(COPYRIGHT_INFO)
self.profile_path = self.get_or_create_profile()
self.driver = self.setup_driver()
if not self.driver:
print("无法初始化WebDriver")
return
self.doc_url = input("请输入百度文库文档URL: ").strip()
if not self.doc_url:
print("未提供URL,程序退出")
return
try:
if self.process_document(self.doc_url):
print(f"捕获到 {len(self.data_urls)} 个数据URL")
print("开始下载数据文件...")
downloaded_files = self.download_data_files()
if downloaded_files:
print(f"\n成功下载 {len(downloaded_files)} 个数据文件")
# 获取所有下载的JS文件
doc_dir = os.path.join(self.output_dir, self.doc_id)
js_files = glob.glob(os.path.join(doc_dir, "*.js"))
if js_files:
# 创建合并后的TXT文件路径(直接保存在文库目录)
clean_title = re.sub(r'[\\/*?:"<>|]', '', self.doc_title)
txt_output_path = os.path.join(self.output_dir, f"{clean_title}.txt")
# 合并JS文件为TXT
print("开始解析并合并文档内容...")
if self.merge_js_files_to_txt(js_files, txt_output_path):
print(f"文档已成功保存至: {txt_output_path}")
# 清理临时文件
self.cleanup_temp_files()
else:
print("文档合并失败")
else:
print("未找到可解析的JS文件")
else:
print("没有可下载的文件")
else:
print("文档处理失败")
except Exception as e:
print(f"处理过程中出错: {str(e)}")
traceback.print_exc()
finally:
if self.capture_thread:
self.capture_thread.stop()
self.capture_thread.join(timeout=2)
if self.driver:
self.driver.quit()
self.session.close()
print("\n吾爱破解论坛 - www.52pojie.cn")
print("作者:pansuan")
print("本工具仅供学习交流,严禁商业倒卖!")
if __name__ == "__main__":
downloader = BaiduWenkuDownloader()
downloader.main()
[免责声明:仅限用于学习和研究目的;不得将上述内容用于商业或者非法用途,否则,一切后果请用户自负。您必须在下载后的24个小时之内,从您的电脑或手机中彻底删除上述内容。]
文档信息
- 本文作者:pansuan
- 本文链接:https://pan.pansuan.xyz/2025/06/29/python-wenku-TXT-with-python/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享4.0许可证)