
示例网站 PDF方法 就是直接加载完全页面,然后捕捉出渲染完成的图片
import os
import time
import base64
import logging
import re
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from PIL import Image
# 配置日志
def setup_logging():
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# 简洁的控制台日志格式
console_handler = logging.StreamHandler()
console_handler.setFormatter(logging.Formatter('%(message)s'))
logger.addHandler(console_handler)
setup_logging()
# 配置参数
DOWNLOAD_DIR = r"C:\Users\16272\Downloads\文库"
SAVE_DIR = os.path.join(DOWNLOAD_DIR, "图片")
PDF_DIR = os.path.join(DOWNLOAD_DIR, "PDF")
USER_PROFILE = r"D:\python\pythonProject1\xuexi\chrome_profile"
MAX_PAGES = 100 # 最大爬取页数
HEADLESS = False # 设置为True启用无头模式(无界面后台运行)
# 确保目录存在
os.makedirs(DOWNLOAD_DIR, exist_ok=True)
os.makedirs(SAVE_DIR, exist_ok=True)
os.makedirs(PDF_DIR, exist_ok=True)
os.makedirs(USER_PROFILE, exist_ok=True)
def sanitize_filename(filename):
"""清理文件名,移除非法字符"""
illegal_chars = r'[<>:"/\\|?*\x00-\x1f]'
clean_name = re.sub(illegal_chars, '_', filename)
return clean_name[:100] # 缩短过长的文件名
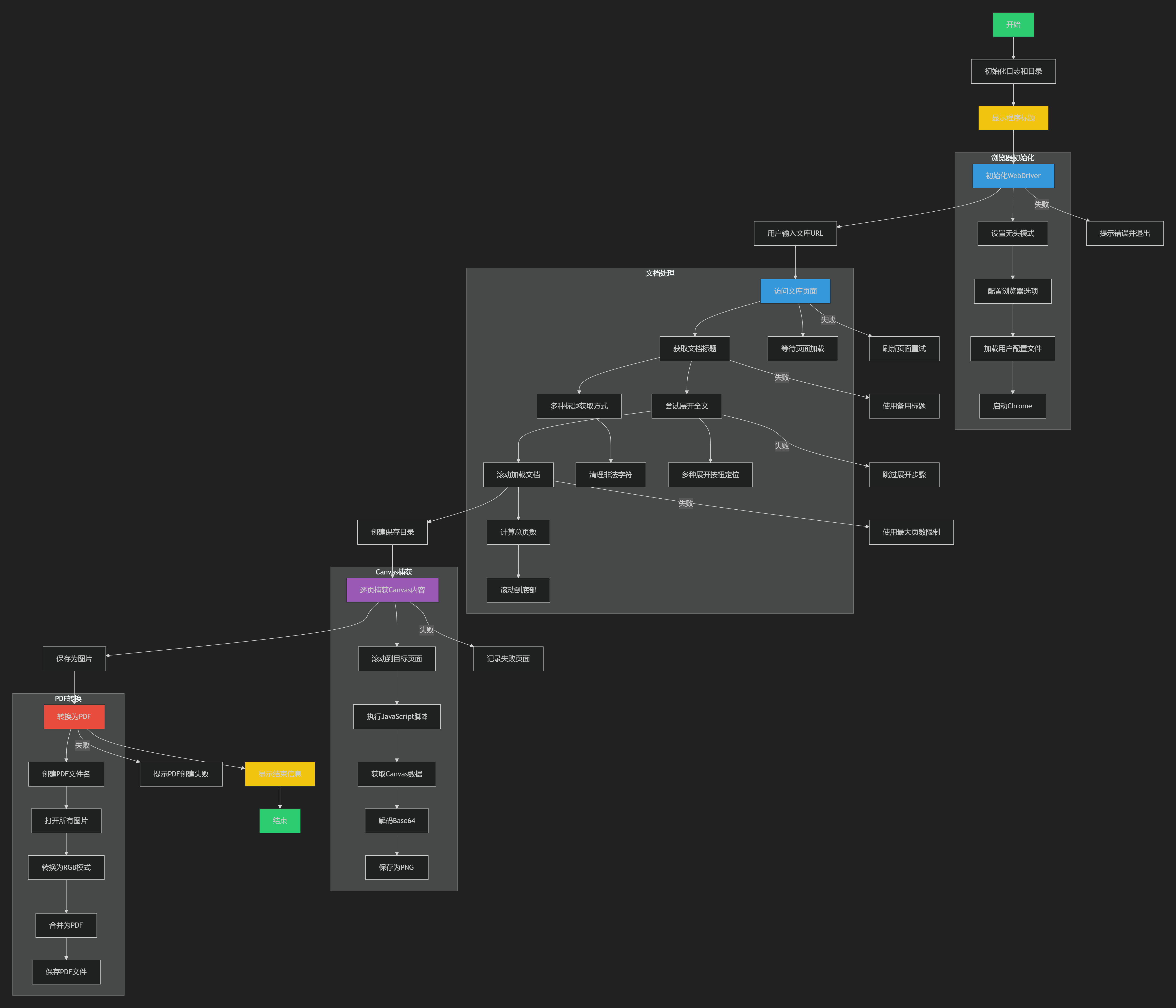
class WenkuCapture:
def __init__(self, driver):
self.driver = driver
self.total_pages = 0
self.document_title = ""
def get_document_title(self):
"""获取文档标题"""
try:
# 尝试多种选择器获取标题
try:
title_element = WebDriverWait(self.driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "div.doc-title-text"))
)
self.document_title = title_element.text.strip()
except:
title_element = self.driver.find_element(By.CSS_SELECTOR, "h1.doc-title")
self.document_title = title_element.text.strip()
# 清理标题
self.document_title = sanitize_filename(self.document_title)
logging.info(f"文档标题: {self.document_title}")
return True
except Exception:
# 使用URL作为备选标题
url = self.driver.current_url
if "view/" in url:
doc_id = url.split("view/")[1].split(".")[0]
self.document_title = f"文库文档_{doc_id}"
else:
self.document_title = f"文库文档_{time.strftime('%Y%m%d%H%M%S')}"
logging.info(f"使用备选标题: {self.document_title}")
return False
def click_unfold_button(self):
"""尝试点击'查看剩余全文'按钮"""
try:
# 尝试使用CSS选择器定位按钮
try:
unfold_btn = WebDriverWait(self.driver, 3).until(
EC.element_to_be_clickable(
(By.CSS_SELECTOR, '.btn.unfold.light, .read-all-btn, .reader-topbanner-expand'))
)
unfold_btn.click()
time.sleep(2) # 等待内容加载
return True
except:
pass
# 如果CSS选择器失败,尝试通过文本定位
try:
buttons = self.driver.find_elements(By.TAG_NAME, 'button')
for btn in buttons:
if '查看剩余全文' in btn.text or '展开全部' in btn.text or '继续阅读' in btn.text:
btn.click()
time.sleep(2)
return True
except:
pass
# JavaScript点击作为后备方案
js_script = """
var selectors = ['.btn.unfold.light', '.read-all-btn', '.reader-topbanner-expand'];
for (var i = 0; i < selectors.length; i++) {
var button = document.querySelector(selectors[i]);
if (button) { button.click(); return true; }
}
return false;
"""
if self.driver.execute_script(js_script):
time.sleep(2)
return True
return False
except Exception:
return False
def scroll_document(self):
"""滚动加载所有内容"""
try:
# 获取文档容器
container = WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#original-creader-root"))
)
# 获取所有页面元素
pages = self.driver.find_elements(By.CSS_SELECTOR, "#original-creader-root > .pageNo")
self.total_pages = len(pages)
logging.info(f"发现 {self.total_pages} 页文档")
if self.total_pages == 0:
return False
# 滚动到底部加载所有内容
self.driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(3)
return True
except Exception:
return False
def capture_wenku_canvas(driver, page_number, session_dir):
"""专门针对百度文库的Canvas渲染特性进行截图"""
try:
# 生成文件名
filename = f"page_{page_number}.png"
save_path = os.path.join(session_dir, filename)
# 查找Canvas容器
container = driver.find_element(By.CSS_SELECTOR, f"#original-pageNo-{page_number}")
# 执行JavaScript获取Canvas内容
script = """
var canvas = arguments[0].querySelector('canvas.creader-canvas');
if (!canvas) return null;
var width = canvas.width;
var height = canvas.height;
var tempCanvas = document.createElement('canvas');
tempCanvas.width = width;
tempCanvas.height = height;
var ctx = tempCanvas.getContext('2d');
ctx.fillStyle = 'white';
ctx.fillRect(0, 0, width, height);
ctx.drawImage(canvas, 0, 0, width, height);
return tempCanvas.toDataURL('image/png').split(',')[1];
"""
# 执行脚本获取图像数据
data_url = driver.execute_script(script, container)
if not data_url:
return None
# 解码base64数据并保存
with open(save_path, "wb") as f:
f.write(base64.b64decode(data_url))
return save_path
except Exception:
return None
def capture_pages(driver, url):
"""捕获文库Canvas内容并保存为图片"""
logging.info(f"正在访问: {url}")
driver.get(url)
time.sleep(5) # 等待页面加载
# 创建文库捕获工具
wenku_capture = WenkuCapture(driver)
# 获取文档标题
wenku_capture.get_document_title()
# 尝试展开全文
if wenku_capture.click_unfold_button():
logging.info("已展开全文")
# 滚动加载所有内容
wenku_capture.scroll_document()
# 创建保存目录
session_dir = os.path.join(SAVE_DIR, time.strftime("%Y%m%d-%H%M%S"))
os.makedirs(session_dir, exist_ok=True)
# 捕获每个页面
screenshots = []
total_pages = wenku_capture.total_pages or MAX_PAGES
logging.info(f"开始捕获 {total_pages} 页内容...")
for i in range(1, min(total_pages, MAX_PAGES) + 1):
try:
# 滚动到页面位置(无头模式需要执行JavaScript)
driver.execute_script(
f"document.getElementById('original-pageNo-{i}').scrollIntoView();")
time.sleep(0.5) # 等待渲染
# 添加额外等待时间确保内容加载
WebDriverWait(driver, 5).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, f"#original-pageNo-{i}")))
except:
pass
# 捕获页面内容
saved_path = capture_wenku_canvas(driver, i, session_dir)
if saved_path:
screenshots.append(saved_path)
logging.info(f"已保存第 {i} 页")
else:
logging.info(f"第 {i} 页捕获失败")
# 尝试重新加载页面
if i == 1:
logging.info("尝试重新加载页面...")
driver.refresh()
time.sleep(5)
saved_path = capture_wenku_canvas(driver, i, session_dir)
if saved_path:
screenshots.append(saved_path)
logging.info(f"重新加载后成功保存第 {i} 页")
logging.info(f"捕获完成,共保存 {len(screenshots)} 页")
return screenshots, wenku_capture.document_title
def convert_to_pdf(image_paths, document_title):
"""将图片转换为PDF"""
if not image_paths:
logging.warning("没有图片可转换")
return None
# 创建PDF文件名
filename = f"{document_title}_{time.strftime('%Y%m%d%H%M%S')}.pdf"
pdf_path = os.path.join(PDF_DIR, filename)
# 使用PIL创建PDF
images = []
for img_path in image_paths:
try:
img = Image.open(img_path)
if img.mode == 'RGBA':
img = img.convert('RGB')
images.append(img)
except:
pass
# 保存PDF
if images:
images[0].save(pdf_path, "PDF", save_all=True, append_images=images[1:])
logging.info(f"已创建PDF: {pdf_path}")
return pdf_path
return None
def init_webdriver(driver_path, profile_path):
"""初始化WebDriver使用用户配置文件"""
options = webdriver.ChromeOptions()
# 添加无头模式选项
if HEADLESS:
options.add_argument('--headless=new')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
else:
# 有头模式下的优化
options.add_argument('--start-maximized') # 最大化窗口
options.add_argument('--disable-infobars') # 禁用信息栏
options.add_experimental_option("excludeSwitches", ["enable-automation"]) # 隐藏自动化控制提示
# 解决图片加载问题
options.add_argument('--blink-settings=imagesEnabled=true') # 确保图片加载
options.add_argument('--disable-images') # 禁用图片拦截
# 禁用可能导致拦截的扩展
options.add_argument('--disable-extensions')
# 常规选项
options.add_argument(f"user-data-dir={profile_path}")
options.add_argument('--disable-web-security')
options.add_argument('--window-size=1920,1080') # 设置窗口大小
# 解决资源拦截问题
prefs = {
"profile.managed_default_content_settings.images": 1, # 允许加载图片
"profile.managed_default_content_settings.javascript": 1, # 允许JavaScript
"profile.managed_default_content_settings.stylesheets": 1, # 允许CSS
"profile.managed_default_content_settings.plugins": 1, # 允许插件
"profile.managed_default_content_settings.popups": 2, # 允许弹出窗口
}
options.add_experimental_option("prefs", prefs)
try:
service = Service(executable_path=driver_path)
driver = webdriver.Chrome(service=service, options=options)
# 设置页面加载超时
driver.set_page_load_timeout(60)
driver.set_script_timeout(60)
return driver
except Exception as e:
logging.error(f"浏览器初始化失败: {str(e)}")
return None
def display_banner():
"""显示程序标题和版权信息"""
banner = f"""
============================================================
吾爱破解论坛 - www.52pojie.cn
作者:pansuan
============================================================
警告:本工具仅供技术交流与学习使用,严禁用于商业倒卖!
任何未经授权的商业使用均属侵权行为,将承担法律责任。
============================================================
"""
print(banner)
def display_footer():
"""显示程序结束信息"""
footer = """
============================================================
吾爱破解论坛 - www.52pojie.cn
作者:pansuan
============================================================
警告:本工具仅供技术交流与学习使用,严禁用于商业倒卖!
任何未经授权的商业使用均属侵权行为,将承担法律责任。
============================================================
"""
print(footer)
def main():
DRIVER_PATH = r"D:\python\pythonProject1\xuexi\chromedriver.exe"
# 显示程序标题
display_banner()
# 初始化WebDriver
driver = init_webdriver(DRIVER_PATH, USER_PROFILE)
if not driver:
logging.error("无法初始化浏览器")
return
try:
url = input("请输入文库URL: ")
screenshots, document_title = capture_pages(driver, url)
if screenshots:
pdf_path = convert_to_pdf(screenshots, document_title)
if pdf_path:
logging.info(f"处理完成! PDF已保存至: {pdf_path}")
else:
logging.warning("PDF创建失败")
else:
logging.warning("未成功保存任何页面")
except Exception as e:
logging.error(f"处理错误: {str(e)}")
finally:
driver.quit()
display_footer() # 显示结束信息
if __name__ == "__main__":
main()
[免责声明:仅限用于学习和研究目的;不得将上述内容用于商业或者非法用途,否则,一切后果请用户自负。您必须在下载后的24个小时之内,从您的电脑或手机中彻底删除上述内容。]
文档信息
- 本文作者:pansuan
- 本文链接:https://pan.pansuan.xyz/2025/06/28/python-wenku-PDF-with-python/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享4.0许可证)