
word可编辑格式 这种是可以在线编辑的word,那么就可以直接从网页中提取文本流 示例网站 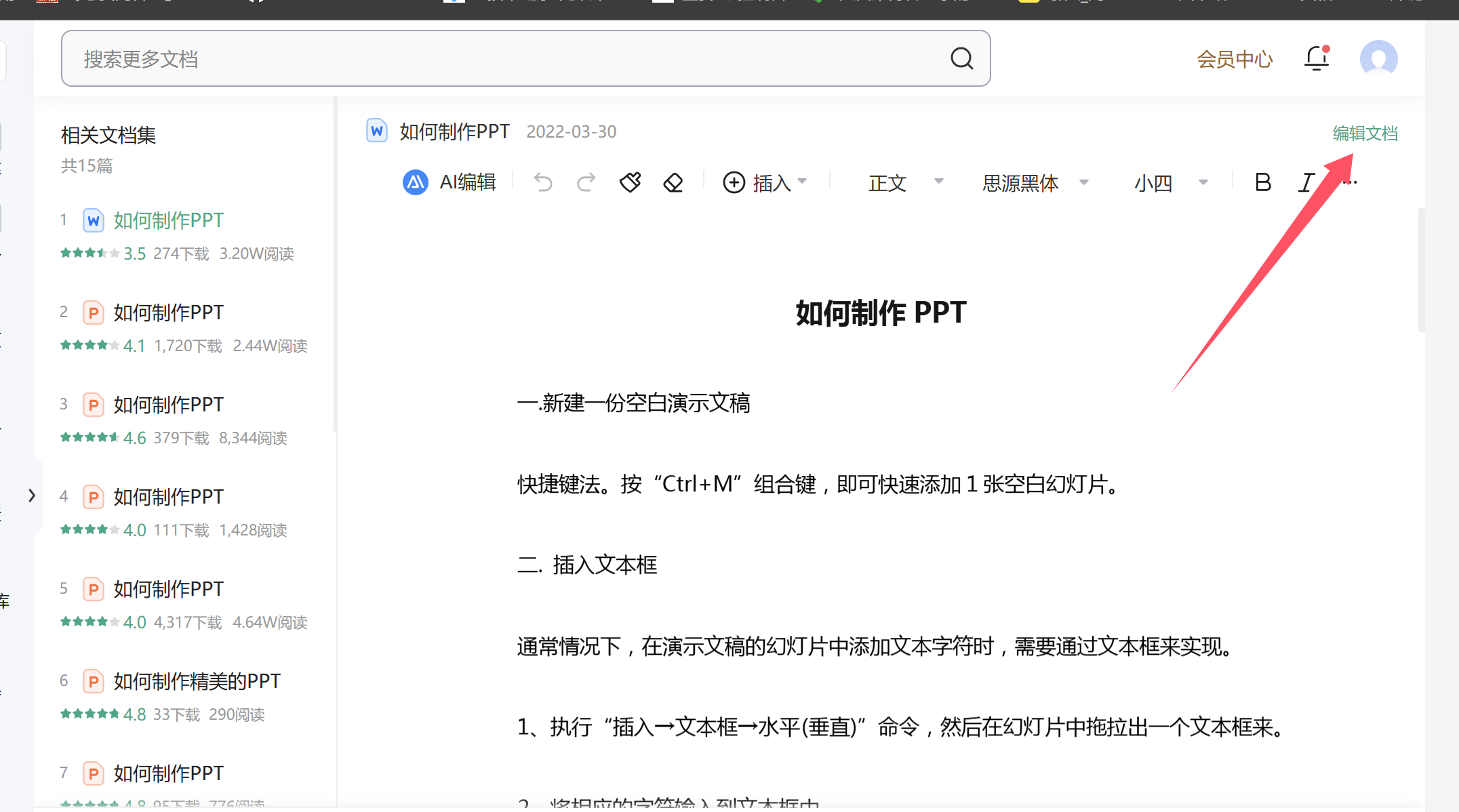 直接打开控制台,用元素定位他,直接就写在页面了,而且,其中也会包含有图片的,所以我们要既提取文本流,也要将图片插入到文档中。
直接打开控制台,用元素定位他,直接就写在页面了,而且,其中也会包含有图片的,所以我们要既提取文本流,也要将图片插入到文档中。 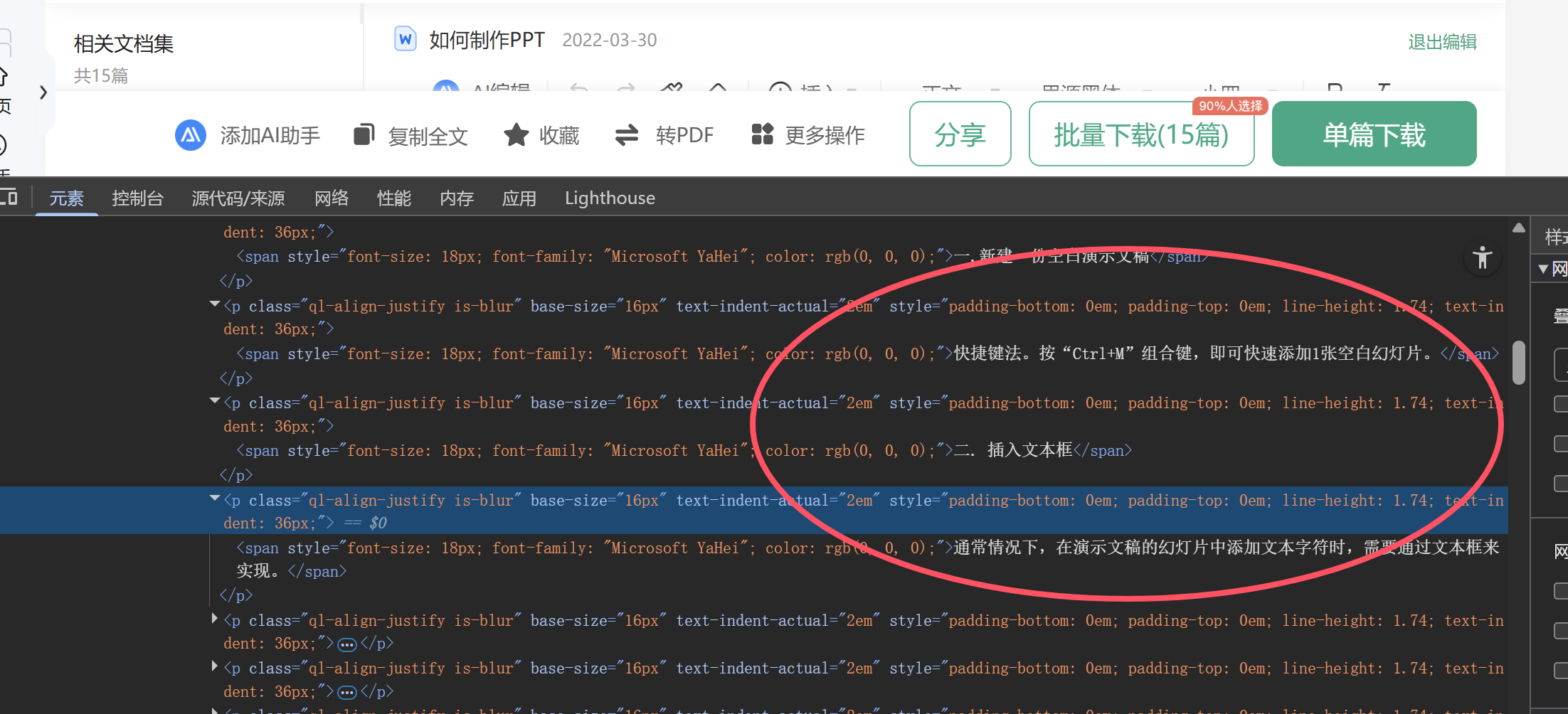 有一个难点我不会解决,就是图片插入的大小,这个我不知道怎么控制,所以输出的文件,还得自己调整图片大小
有一个难点我不会解决,就是图片插入的大小,这个我不知道怎么控制,所以输出的文件,还得自己调整图片大小
import os
import re
import time
import random
import requests
import json
import urllib.parse
from io import BytesIO
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from docx import Document
from docx.shared import Inches, Cm, Pt
from docx.enum.text import WD_ALIGN_PARAGRAPH
from bs4 import BeautifulSoup
from PIL import Image
import base64
import io
# 保存路径设置
DOWNLOAD_DIR = r"C:\Users\16272\Downloads\文库"
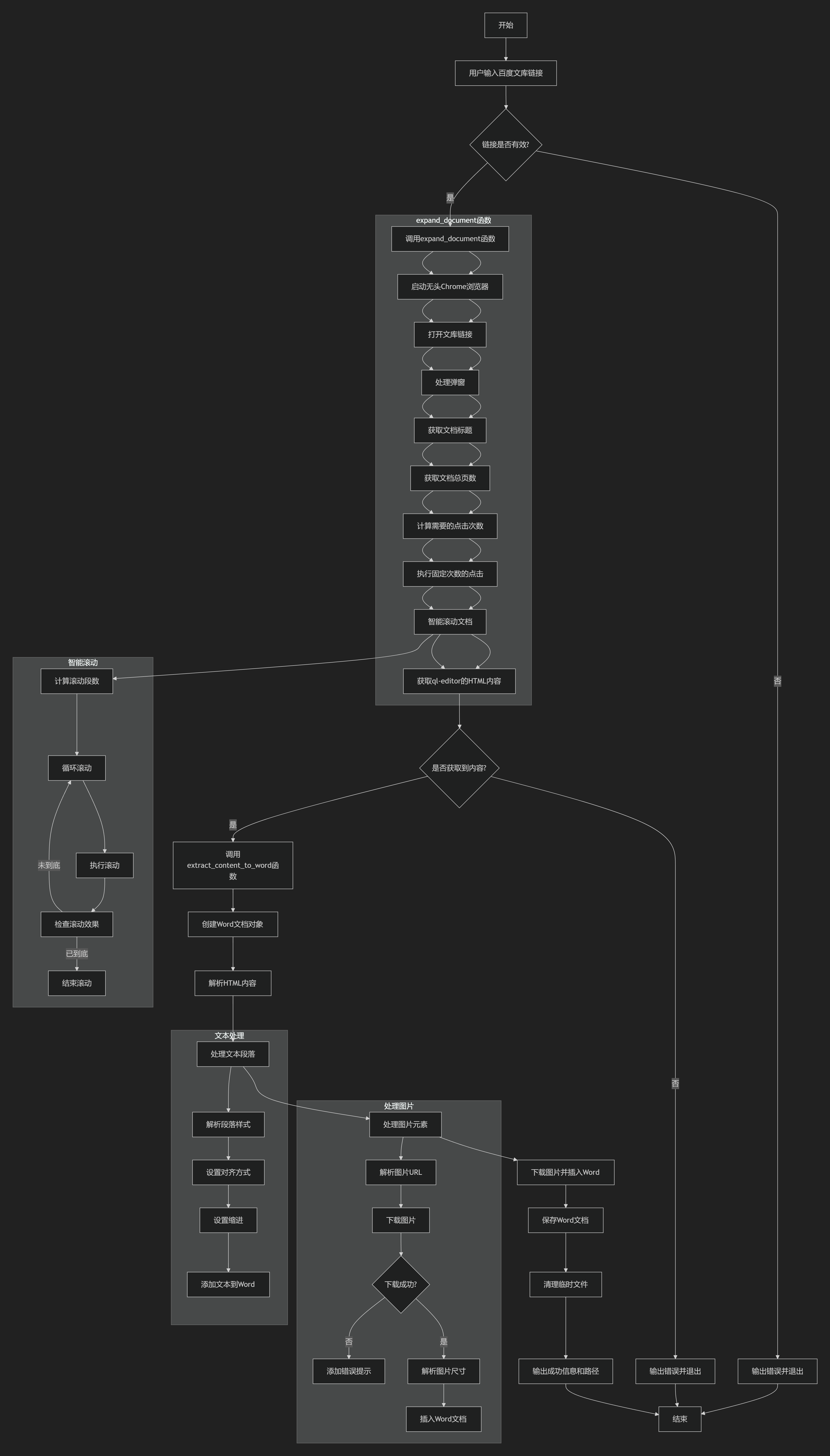
def expand_document(url):
"""主函数:展开文档内容并返回网页源代码和标题"""
# 配置浏览器选项
chrome_options = Options()
chrome_options.add_argument(r"user-data-dir=D:\python\pythonProject1\xuexi\chrome_profile")
chrome_options.add_argument("--headless")
# 创建Chrome服务
chrome_service = Service(executable_path=r"D:\python\pythonProject1\xuexi\chromedriver.exe")
# 初始化浏览器
driver = webdriver.Chrome(service=chrome_service, options=chrome_options)
driver.set_window_size(1280, 1024)
html_content = ""
document_title = "百度文库文档"
try:
# 1. 打开指定的百度文库文档
print(f"正在打开文档: {url}")
driver.get(url)
time.sleep(3)
# 2. 处理弹窗
handle_popups(driver)
# 3. 获取文档标题
try:
title_element = driver.find_element(By.CSS_SELECTOR, '.doc-title-text')
document_title = title_element.text.strip()
print(f"获取文档标题: {document_title}")
except Exception as e:
print(f"获取文档标题失败: {str(e)}")
# 4. 获取文档实际页数
total_pages = get_total_pages(driver)
if total_pages is None:
total_pages = 1
print(f"检测到文档实际共 {total_pages} 页")
# 5. 执行固定次数的点击
clicks_needed = calculate_clicks_needed(total_pages)
print(f"需要执行 {clicks_needed} 次点击操作")
perform_fixed_clicks(driver, clicks_needed)
# 6. 智能滚动查看文档
if total_pages > 0:
print("开始滚动文档...")
scroll_document_by_pages(driver, total_pages)
time.sleep(2) # 等待加载
# 7. 获取指定的ql-editor元素内容
ql_editor = driver.find_element(By.CSS_SELECTOR, '.ql-editor')
html_content = ql_editor.get_attribute("innerHTML")
print(f"已获取ql-editor内容,长度: {len(html_content)} 字符")
except Exception as e:
print(f"处理过程中发生错误: {str(e)}")
finally:
driver.quit()
return html_content, document_title
def get_total_pages(driver):
"""获取文档总页数"""
try:
# 尝试从文档结构中获取页数
pages = driver.find_elements(By.CSS_SELECTOR, '.page-wrapper, .ppt-page, .page-item')
if pages:
return len(pages)
# 尝试从文本中解析页数
page_info = driver.find_element(By.CSS_SELECTOR, "div.page-tips").text
if page_info:
match = re.search(r'原始文档\s*共\s*(\d+)\s*页', page_info)
if match:
return int(match.group(1))
# 基于高度估算页数
doc_height = driver.execute_script("return document.documentElement.scrollHeight")
view_height = driver.execute_script("return window.innerHeight")
if doc_height > 0 and view_height > 0:
return max(1, round(doc_height / view_height))
except Exception:
pass
return 1 # 默认值
def calculate_clicks_needed(total_pages):
"""计算需要的点击次数"""
# 基于文档页数确定点击次数
if total_pages <= 10:
return 1
elif total_pages <= 50:
return 2
elif total_pages <= 100:
return 3
elif total_pages <= 200:
return 4
else:
return 5
def perform_fixed_clicks(driver, clicks_needed):
"""执行固定次数的点击操作"""
for click_count in range(clicks_needed):
try:
# 尝试多种选择器查找展开按钮
selectors = [
"div.moreBtn",
"div.unfold-btn",
"div.fold-button",
"div.btn.unfold.light",
".unfold-btn"
]
for selector in selectors:
try:
expand_btn = WebDriverWait(driver, 2).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, selector))
)
driver.execute_script("arguments[0].scrollIntoView();", expand_btn)
driver.execute_script("arguments[0].click();", expand_btn)
time.sleep(random.uniform(1.0, 1.5))
print(f"点击了展开按钮 ({click_count + 1}/{clicks_needed})")
break
except:
continue
except Exception as e:
print(f"点击操作失败: {str(e)}")
time.sleep(0.5)
def handle_popups(driver):
"""处理弹窗"""
try:
# 尝试点击继续阅读按钮
continue_btn = WebDriverWait(driver, 3).until(
EC.element_to_be_clickable(
(By.XPATH, "//div[contains(text(), '查看剩余全文') or contains(text(), '点击继查看剩余全文')]")
)
)
continue_btn.click()
time.sleep(1)
except:
pass
try:
# 尝试关闭登录提示
close_btn = WebDriverWait(driver, 2).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "div.close-btn, span.banner-close, .dialog-close"))
)
close_btn.click()
except:
pass
def scroll_document_by_pages(driver, total_pages):
"""智能滚动文档内容"""
# 计算分段数(根据文档长度确定滚动次数)
segments = min(30, max(5, total_pages // 3))
# 记录当前滚动位置
last_height = driver.execute_script("return document.documentElement.scrollTop")
for i in range(segments):
# 计算目标滚动位置(文档总高度的一部分)
scroll_target = int(driver.execute_script("return document.documentElement.scrollHeight") * (i + 1) / segments)
# 执行滚动
driver.execute_script(f"window.scrollTo(0, {scroll_target});")
time.sleep(random.uniform(0.3, 0.8)) # 随机等待时间模拟阅读
# 检查滚动是否生效
new_height = driver.execute_script("return document.documentElement.scrollTop")
if new_height == last_height:
# 可能已到达底部,提前结束
break
last_height = new_height
def download_image(img_url):
"""下载图片并返回二进制数据"""
headers = {
'User-Agent': 'Mozilla/5.5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Referer': 'https://wenku.baidu.com/'
}
orig_width = orig_height = None
try:
# 处理百度文库特定的图片URL
if 'wkrtcs.bdimg.com' in img_url:
# 解码URL参数
parsed_url = urllib.parse.urlparse(img_url)
query_params = urllib.parse.parse_qs(parsed_url.query)
# 提取原始图片尺寸
if 'ipr' in query_params:
ipr_str = query_params['ipr'][0]
# 修复JSON格式
try:
ipr_data = json.loads(ipr_str)
if 'imgOriW' in ipr_data and 'imgOriH' in ipr_data:
orig_width = int(ipr_data['imgOriW'])
orig_height = int(ipr_data['imgOriH'])
print(f"获取原始图片尺寸: {orig_width}x{orig_height}")
except json.JSONDecodeError:
# 尝试多次修复常见JSON格式问题
ipr_str = ipr_str.replace("'", "\"").replace('\\"', '"')
try:
ipr_data = json.loads(ipr_str)
if 'imgOriW' in ipr_data and 'imgOriH' in ipr_data:
orig_width = int(ipr_data['imgOriW'])
orig_height = int(ipr_data['imgOriH'])
except:
print("无法解析ipr参数")
# 如果URL包含base64数据,直接解码
if img_url.startswith('data:image'):
# 格式: data:image/png;base64,XXXXX
img_data = base64.b64decode(img_url.split(',')[1])
return img_data, orig_width, orig_height
# 下载图片
response = requests.get(img_url, headers=headers, timeout=10)
if response.status_code == 200:
return response.content, orig_width, orig_height
except Exception as e:
print(f"下载图片失败: {str(e)}")
return None, None, None
def extract_content_to_word(html_content, document_title):
"""从ql-editor HTML内容中提取文本和图片,并保存为Word文档"""
# 创建Word文档
document = Document()
# 添加文档标题
document.add_heading(document_title, level=0)
document.add_paragraph() # 添加空行
# 设置默认字体
style = document.styles['Normal']
font = style.font
font.name = '宋体'
font.size = Pt(10.5)
# 创建图片保存目录
img_dir = os.path.join(DOWNLOAD_DIR, "temp_images")
os.makedirs(img_dir, exist_ok=True)
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 遍历所有元素
elements = soup.find_all(['p', 'img'])
for element in elements:
if element.name == 'p':
# 处理文本段落
classes = element.get('class', [])
paragraph = document.add_paragraph()
# 设置段落对齐方式
if 'ql-align-center' in classes:
paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER
elif 'ql-align-right' in classes:
paragraph.alignment = WD_ALIGN_PARAGRAPH.RIGHT
# 保留文本格式
text_content = element.get_text()
# 保留换行符(使用Unicode的LINE SEPARATOR)
text_content = text_content.replace('\n', u'\u2028')
run = paragraph.add_run(text_content)
# 设置缩进
if 'is-blur' in classes:
paragraph_format = paragraph.paragraph_format
paragraph_format.first_line_indent = Cm(1.0) # 缩进1厘米
elif element.name == 'img':
# 处理图片
img_src = element.get('src') or element.get('data-src')
if not img_src:
continue
# 处理相对路径
if not img_src.startswith('http'):
img_src = f'https:{img_src}'
# 获取图片原始尺寸信息
img_width = element.get('width', '0')
img_style = element.get('style', '')
# 尝试从样式中解析宽度
width_match = re.search(r'width:\s*(\d+\.?\d*)\s*px', img_style)
if width_match:
img_width = float(width_match.group(1))
# 下载图片
try:
img_data, orig_width, orig_height = download_image(img_src)
if img_data:
print(f"成功下载图片: {img_src}")
# 获取实际图片尺寸
img = Image.open(io.BytesIO(img_data))
img_width_px, img_height_px = img.size
# 使用原始尺寸(如果可用)
if orig_width and orig_height:
img_width_px, img_height_px = orig_width, orig_height
# 转换为Word中的厘米(1厘米≈37.8像素)
width_cm = img_width_px / 37.8
# 如果元素中有宽度定义,优先使用元素宽度
if img_width and img_width != '0':
try:
element_width = float(img_width)
# 计算比例(元素宽度 / 实际宽度)
scale = element_width / img_width_px
width_cm = width_cm * scale
except ValueError:
pass
# 限制最大宽度不超过15厘米
width_cm = min(width_cm, 15)
# 保存临时图片
img_name = os.path.join(img_dir, f"image_{int(time.time() * 1000)}.jpg")
with open(img_name, 'wb') as f:
f.write(img_data)
# 添加到Word文档
paragraph = document.add_paragraph()
# 判断图片对齐方式
img_classes = element.get('class', [])
if 'ql-align-center' in img_classes:
paragraph.alignment = WD_ALIGN_PARAGRAPH.CENTER
elif 'ql-align-right' in img_classes:
paragraph.alignment = WD_ALIGN_PARAGRAPH.RIGHT
else:
paragraph.alignment = WD_ALIGN_PARAGRAPH.LEFT
# 添加图片
run = paragraph.add_run()
# 尝试添加图片到文档
try:
inline_shape = run.add_picture(img_name, width=Cm(width_cm))
# 保持纵横比
height_cm = width_cm * (img_height_px / img_width_px)
inline_shape.width = Cm(width_cm)
inline_shape.height = Cm(height_cm)
print(f"插入图片成功,尺寸: {width_cm:.2f}cm x {height_cm:.2f}cm")
except Exception as e:
print(f"添加图片到Word失败: {str(e)}")
# 添加错误提示
error_para = document.add_paragraph()
error_para.add_run(f"[图片插入失败: {img_src}]")
# 添加空格(模拟段落后间距)
document.add_paragraph()
time.sleep(0.2)
except Exception as e:
print(f"处理图片失败: {str(e)}")
# 添加错误提示
error_para = document.add_paragraph()
error_para.add_run(f"[图片下载失败: {img_src}]")
# 生成安全文件名
safe_title = re.sub(r'[\\/*?:"<>|]', '', document_title) # 移除非法字符
output_path = os.path.join(DOWNLOAD_DIR, f"{safe_title}.docx")
# 确保目标目录存在
os.makedirs(DOWNLOAD_DIR, exist_ok=True)
# 保存Word文档
document.save(output_path)
print(f"Word文档已保存到: {output_path}")
# 清理临时图片文件
for file in os.listdir(img_dir):
if file.endswith(".jpg"):
os.remove(os.path.join(img_dir, file))
os.rmdir(img_dir)
return output_path
if __name__ == "__main__":
# 确保下载目录存在
os.makedirs(DOWNLOAD_DIR, exist_ok=True)
# 获取用户输入的百度文库链接
print("百度文库文档提取工具")
print("=" * 40)
print(f"文档将保存到: {DOWNLOAD_DIR}")
print("=" * 40)
url = input("请输入百度文库文档链接: ")
# 验证链接格式
if not url.startswith("https://wenku.baidu.com/view/"):
print("链接格式错误!请确保输入的是百度文库文档链接")
else:
# 1. 展开文档并获取HTML内容
print("\n开始提取文档内容...")
html_content, document_title = expand_document(url)
if html_content:
# 2. 提取内容到Word文档
saved_path = extract_content_to_word(html_content, document_title)
print(f"\n处理完成!文档已保存为: {saved_path}")
else:
print("\n未能获取文档内容")
input("\n按回车键退出...")
[免责声明:仅限用于学习和研究目的;不得将上述内容用于商业或者非法用途,否则,一切后果请用户自负。您必须在下载后的24个小时之内,从您的电脑或手机中彻底删除上述内容。]
文档信息
- 本文作者:pansuan
- 本文链接:https://pan.pansuan.xyz/2025/06/26/python-wenku-WROD-with-python/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享4.0许可证)